内容目录

要使用这个项目的第一个步骤,就是将开源仓内容下载到设备上,请执行以下指令:
$ git clone https://github.com/NVIDIA-AI-IOT/jetson_benchmarks
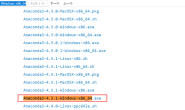
在项目子目录里有个 ”benchmark_csv” 目录,里面有 7 个针对不同设备的.csv 评测配置文件,如果用本文编辑器打开的话,内容大概如下截屏所示:

这样非常不利于了解配置文件里的参数是什么意思,因此为了便于查看文件内容,建议在网页上进行(如下图)。

例如点击”orin-benchmark.csv”文件,会显示以下截屏内容。

以下简单说明以下这个表格的各栏位用途:
- Model Name:神经网络模型;
- FrameWork:训练模型所使用的框架;
- Devices:对于不支持 DLA 加速器的设备来说,或者算法本身不支持 DLA 加速功能的,这里的值就是”1”;对于支持 DLA 的设备与算法来说,就会将 DLA 数量添加进去,例如 Jetson Orin 支持 2 个 DLA,在 inception_v4 算法中的设备数量就是”3”;
- BatchSizeGPU、BatchSizeDLA 与 WS_GPU、WS_DLA 参数:根据设备的内存资源进行调整;
- input、output:神经网络的输入节点与输出节点名称;
- URL:下载模型的链接。
以上是配置文件的主要内容,项目中的 7 个配置文件都是针对不同设备进行优化过,除非您有较高的熟悉度,否则选择合适的文件来进行测试就可以。
在进行测试之前,我们还需要下载所需要的模型文件,这就是配置表中最右边的 URL 栏的位置,不过这些连接全部都放在国外的 DropBox 网盘中,需要有特殊方法进行下载,请自行处理。
在 ”utils” 目录下有个 download_models.py 工具代码,可以为我们这些模型下载的动作,不过在下载之前,我们需要先创建一个存放模型文件的子目录,然后根据所要测试的设备(例如 Jetson Orin Nano 开发套件)执行下载代码。请执行以下指令:
# 在 jetson_benchmark 目录下mkdir modelssudo sh install_requirements.shpython3 utils/download_models.py --all --csv_file_path benchmark_csv/orin-nano-benchmarks.csv --save_dir models
然后就会执行下面的下载任务,存放在刚刚创建的 ”models” 目录下:

最后,执行以下指令,就可以一次进行多个神经网络模型的性能测试:
# 在 jetson_benchmark 目录下sudo python3 benchmark.py --all --csv_file_path benchmark_csv/orin-nano-benchmarks.csv --model_dir models/ --jetson_clocks
现在就开始执行性能测试,整个过程大约 2 个小时。

当然我们也可以使用 ”—model_name” 参数,指定个别模型进行测试,例如下面指令就能单独检测 Tiny-YOLO-v3 模型的性能:
# 在 jetson_benchmark 目录下sudo python3 benchmark.py --model_name tiny-yolov3 --csv_file_path benchmark_csv/orin-nano-benchmarks.csv --model_dir models/ --jetson_clocks
整个过程相当直观,请自行扩展。【完】
相关文章
- Anaconda所有历史版本下载(0)
- 【Python】修改Windows中 pip 的缓存位置与删除 pip 缓存(1)
- 解决python中TypeError: not enough arguments for format string(0)
- ‘%s=%s’ % (k, v) for k, v in params.items(), ^ SyntaxError: Generator expression must be parent(0)
- python pycharm如何全局(整个项目中)搜索指定代码?(CTRL+SHIFT+F)全局字符串搜索(0)